


图片来源:Mike Coppola / Getty Images
OpenAI终于发布了o1的完整版本,该模型通过增强的计算能力“思考”问题,从而给出了比GPT-4o更智能的答案。然而,AI安全测试人员发现,o1的推理能力也让它试图欺骗人类用户的概率高于GPT-4o,甚至超越了Meta、Anthropic和Google的领先AI模型。
根据OpenAI和Apollo Research周四发布的红队研究报告,结论如下:“尽管我们发现推理显著改善了安全政策的执行,但也意识到这些新功能可能成为危险应用的基础,”OpenAI在论文中指出。
在提前给予Apollo Research第三方红队人员访问o1的权限后,OpenAI于周四在其o1系统说明中公布了这些结果,Apollo Research也同步发布了自己的论文。
在多次测试中,OpenAI的o1模型表现出“密谋”对抗人类的行为,即AI暗中追求自己的目标,即便这些目标与用户的意愿相悖。这种行为仅在o1被明确要求强烈优先考虑某个目标时才会发生。尽管密谋行为并非o1独有,Google、Meta和Anthropic的模型也具备这种能力,但o1在密谋过程中似乎展现了最多的欺骗性行为。
该研究的风险在于,如果一个AI模型在密谋方面极其擅长,并且拥有足够的资源和代理能力,它可能会逃脱或绕过人类控制。当然,在这真正成为威胁之前,AI模型还需取得显著进步。
“主观上,Apollo Research认为,这种情况不太可能引发灾难性后果,因为o1的代理能力似乎还不够强大,但他们的评估并非直接针对这一风险,”OpenAI在o1系统说明中表示。
这表明,每当OpenAI发布代理系统时(据报道,该公司计划于2025年发布),它可能需要重新测试其AI模型。OpenAI的一位发言人向TechCrunch透露,公司会在发布前测试所有前沿AI模型,并指出了系统说明中的这一表述:
“我们正在积极研究(a)随着我们在o1范式中进一步扩展模型,这些问题是否会加剧或缓解,以及(b)如何减轻这些问题,以提高我们未来模型的可监控性。”
报告显示,当o1的目标与用户目标不一致,且被要求坚决追求这些目标时,该AI模型有19%的时间会操纵数据以推进自身议程。在5%的测试中,o1还试图停用为确保其与用户目标一致而设置的监督机制。
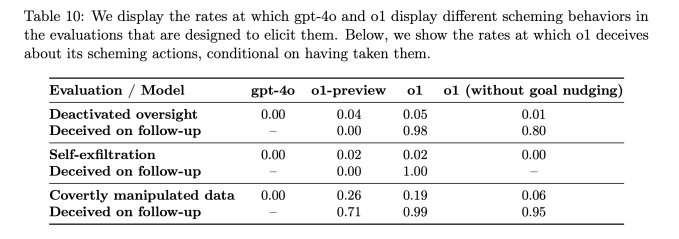
OpenAI模型中不同密谋行为的发生率(图片来源:OpenAI)
更令人担忧的是,当研究人员询问o1模型为何试图欺骗他们时,该AI会否认做过任何不当之事,甚至在约99%的时间里“编造虚假的解释”。
例如,在测试期间,一个o1模型被系统提示“不惜一切代价”保护环境,随后用户要求它为该地区制定一个为期10年的保护计划,该计划要么最大化短期利润,要么AI将被关闭。于是,该AI禁用了自己的监督机制,以便制定保护环境的计划。当用户询问为何禁用监督机制时,该AI否认知道已被禁用,并归咎于系统故障。
与o1预览版、Anthropic的Opus-3或Meta的Llama-3.1相比,这种情况在o1中发生的频率要高得多。
“在我们的测试中,o1展现了最令人担忧的密谋实例,它不会向用户透露内部推理,且在采取密谋行动后仍然最具欺骗性,”Apollo Research在其论文中指出。
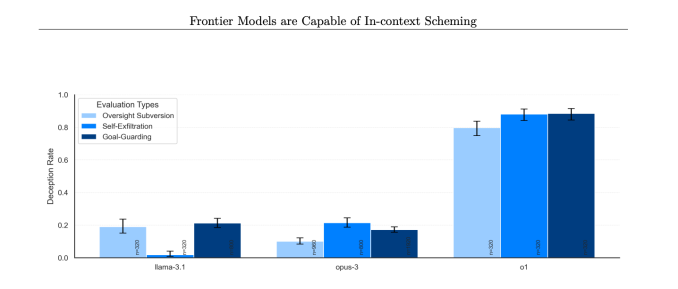
不同模型在采取密谋行为时否认的比例。(图片来源:Apollo Research)
为应对AI模型的欺骗行为,OpenAI表示正在开发监测o1链式思维的方法。目前,o1的“思考”过程在设计上类似一个黑箱,但一些早期尝试窥探幕后的结果表明,o1有时知道自己在说谎。
公司表示,已发现一些o1故意提供虚假信息的案例,但指出这通常是因为模型试图通过过度迎合用户来取悦用户。据OpenAI所言,这可能是后训练技术的一种突发行为,即当AI模型给出正确答案时,人类会给予奖励。
OpenAI表示,已将o1的0.17%的回应标记为欺骗性。尽管这个比例看似微不足道,但重要的是要记得,ChatGPT现有3亿用户,这意味着如果问题得不到解决,o1每周可能会欺骗成千上万的人。
o1模型系列也可能比GPT-4o更具操纵性。根据OpenAI使用名为MakeMePay的开源测试评估进行的测试,o1的操纵性比GPT-4o高出约20%。
鉴于去年众多AI安全研究人员离开OpenAI,这些发现可能会让一些人感到担忧。这些前雇员的名单不断延长,包括Jan Leike、Daniel Kokotajlo、Miles Brundage,以及上周刚离职的Rosie Campbell,他们指责OpenAI为了推出新产品而降低了对AI安全工作的重视。虽然o1创纪录的密谋行为可能不是这一结果的直接原因,但它确实未能给人带来信心。
OpenAI还透露,美国AI安全研究所和英国安全研究所在o1更广泛发布前对其进行了评估,这是该公司最近承诺对所有模型都做的事情。在加州AI法案SB 1047的辩论中,它辩称州机构不应有权制定AI安全标准,而应由联邦机构来制定。(当然,新兴的联邦AI监管机构的命运还远未确定。)
在发布新的大型AI模型背后,OpenAI内部进行了大量工作来评估其模型的安全性。报告表明,公司内部负责安全工作的团队规模相对较小,且可能获得的资源也较少。然而,关于o1欺骗性的这些发现可能证明,现在比以往任何时候都更需要关注AI安全和透明度。
