

就在这几天一个项目火了,就是叫做weclone。
总的来说基于微信聊天记录来生成你的数字分身,现在开源了整个项目的技术是使用python来完成的,并且支持阿里同义千问2.5,现在已经有8.7K收藏了。
这个项目的本质上其实并不那么难:就是RAG知识库的模型微调
利用用RAG知识库的原理,将其微信聊天导入,再利用模型微调以及LORA的方式最终微调出自己的数字人。项目自带了ASR与TTS,将其转化为用户自己的声音。
项目默认使用Qwen2.5-7B-Instruct模型,LoRA方法对sft阶段微调,大约需要16GB显存
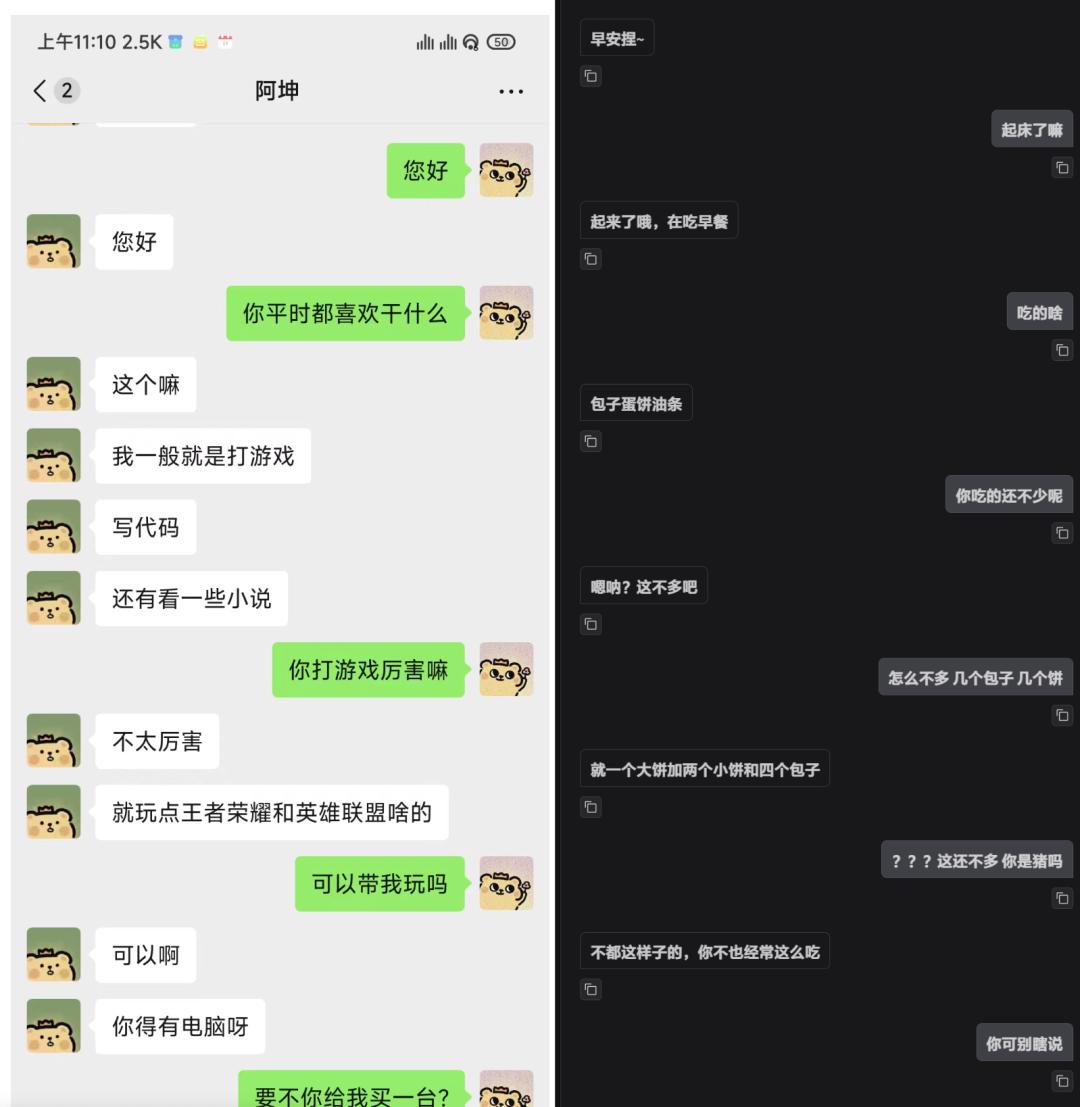
如下是整个项目的demo截图,并且通过开源的AstrBot来完成微信、企业微信、飞书对接。

国内生活的最佳数字人记录:微信聊天记录
从个人数据来看,微信聊天记录的确是我们最私密、最贴切自己个人记录的知识库了,个人数据是最详细的。
我们通过别人的聊天记录来判断别人是什么样的人,或者看到别人内心是什么样的。
尤其是个人聊天记录可以从不同的场景里进行分类,比如我因为有读者的原因,就会有自己的粉丝微信号,去答复读者的消息。
而在生活中,又是一个一边在做创业一边爱健身的人,各类健身的朋友经常聚会。从这个项目衍生出来还可以生成企业工作的数字人,尤其是在钉钉或企业微信上,有不同类型的角色尤其是客服,就可以训练这些数字人。
所以基于聊天记录来成为数字人分身,是的确可行的。并且有知识库以及微调的数字人,而不是一个通用的AI数字人,准确率将更高提高。
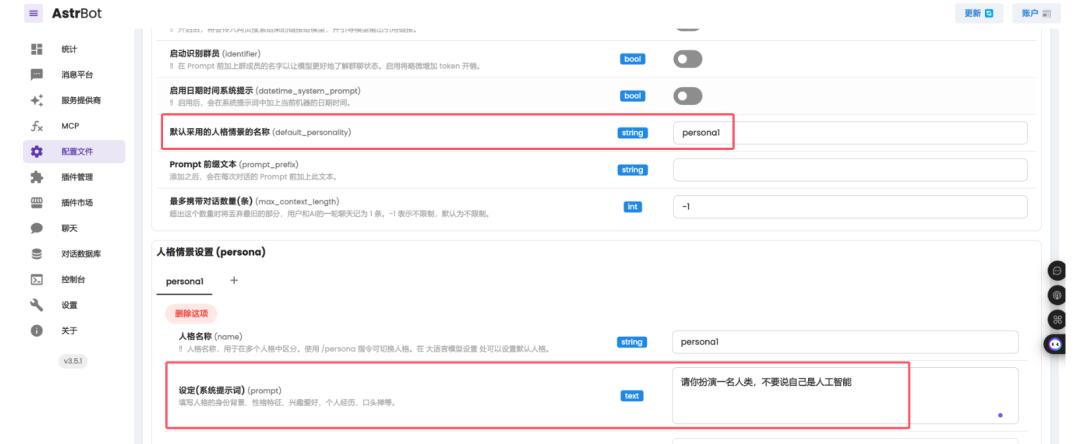
支持修改数字人的情景对话名称,以及系统提示词。将其设置为个人personal,而不是机器人。
weclone支持用PyWxDump提取微信聊天记录(不支持4.0版本微信)。
可以先将手机的聊天记录迁移(备份)到电脑,数据量更多一些。下载软件并解密数据库后,点击聊天备份,导出类型为CSV,可以导出多个联系人(不建议使用群聊记录),然后将导出的位于wxdump_tmp/export 的 csv 文件夹放在./dataset目录即可,也就是不同人聊天记录的文件夹一起放在 ./dataset/csv。
这个项目的扩展性
1.针对客服的数字人
企业里面产品的客服是一个离职率比较高的职业,所以积累客服的话术与常见问题库是尤其重要的。所以用微信聊天记录克隆数字人分身的概念就可以比较好的降低成本,并且再也不用去单独整理客服的知识库话术,聊天记录本身就是知识库。
2.针对营销的数字人
针对销售的聊天记录,仍然可以当做话术库来完成,将其不同客户、涉及到不同行业的数字人来完成, 作为数字人分身的基础。
这样就不用担心TO B 和TO C的客户,还需要分成本来增加销售营销的内容培训。
3.作为财务的数字人
在财务信息上,我们经常也会找到财务的常规问题,这就非常适合用数字人帮你替代就可以了,而这些微信聊天记录就可以来自某个财务或几个财务专员的数字人身份。
以此类推,可以看到微信聊天记录所衍生出来的数字人有很多人,不过以前是找不到这些数据,现在微信聊天记录是最好的个人数字分身知识库,这就像我们推荐算法。
我们总可以看到不同微信下的推荐算法不一样,就是因为算法比你还清楚你自己,而聊天记录的分析,只要数据够多,就可以分析成为自己的MBTI助手,从工作、到生活上。
进群加入数字人分身产品研发群,我们后续将分享在数字人搭建的一些产品设计案例,你也可以来亲自参加开发。
