

ChatGPT新版记忆功能居然被民间大佬逆向工程了!
能引用历史记录,甚至还能悄悄藏个人资料?

最近OpenAI推出了一项名为聊天历史记录的额外记忆功能,允许ChatGPT引用历史对话以进行个性化交互。
相较于原有的保存记忆功能,新功能更私人、更懂你。

相关功能默认关闭,需要用户自行在“设置->个性化->参考聊天记录”中启用。
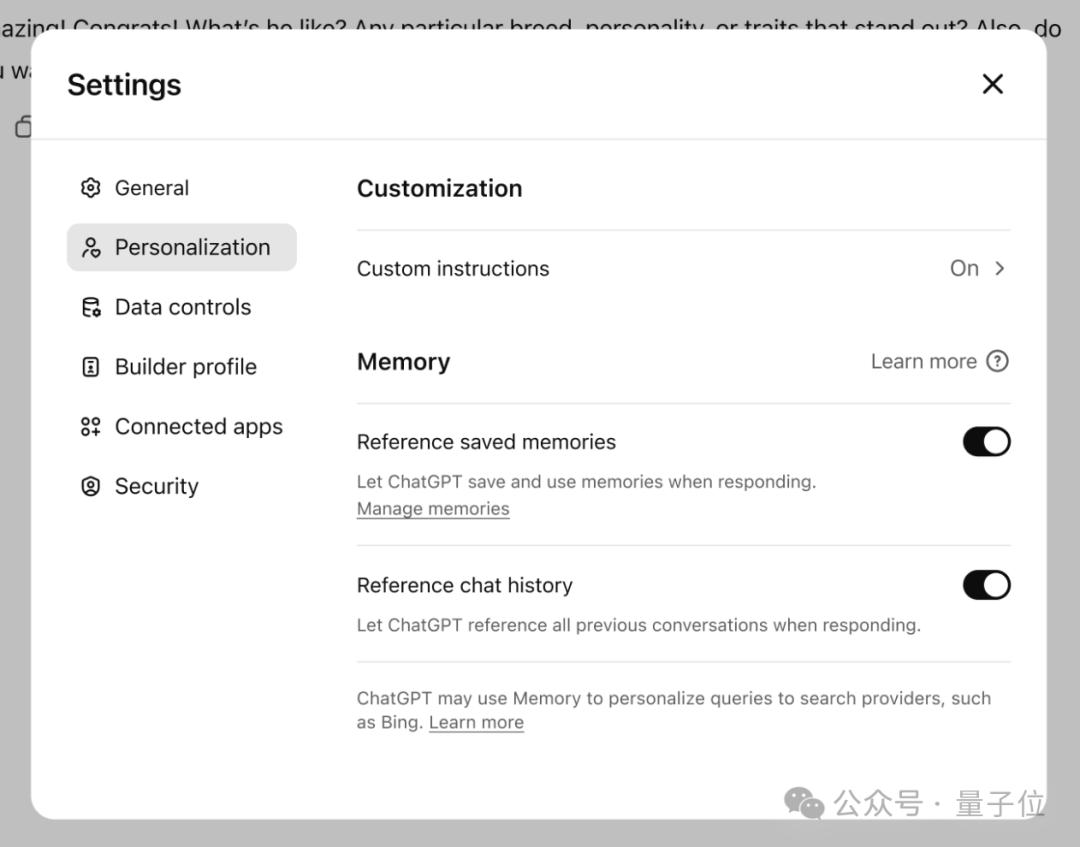
非全面开放、无法通过API供开发者使用,于是各路技术大佬开始着手破解起新记忆功能的具体机制和技术实现路径,甚至披露了连官方都没有透露的聊天记录系统的三大子系统细节。
那记忆功能到底是怎么工作的呢?结合多位大佬的分析,我们总结如下:
记忆系统是如何工作的
据官网介绍,目前已知存在两种记忆功能:参考保存记忆和参考聊天记录。
但在具体实验中发现,聊天记录系统实际上可以细分为当前对话历史记录、对话历史记录和用户洞察三个子系统。
接下来我们依次进行单独阐述。
保存记忆系统
首先是大家最熟悉的保存记忆系统,简单、用户可控,用以保存用户自定义信息,例如你的姓名、喜欢的颜色或饮食偏好。
这些信息会被引入系统提示,用户需要使用类似“Remember that I …”的提示明确要求ChatGPT记住。此外还可以通过用户界面查看和删除信息。
具体的实现过程如下:
由于ChatGPT通过bio工具保存记忆,可以使用以下代码创建工具的合理近似值:

将其定义为LLM调用,以接受用户消息和现有事实列表,然后返回新事实列表或拒绝,此外需要进行测试和迭代以确保行为正确。

以上便完成了用户信息到系统提示的注入。另外如果想要实现与ChatGPT的功能对等,还可以再构建一个简单的UI来检查和删除这些信息。
聊天记录系统
而新功能聊天记录系统实际要复杂得多,且很有可能在助手响应速度的提升中发挥重要作用。
- 当前对话历史记录
这是用户在其他对话中发送的近期消息的简单记录,小到只包含最近一天的信息。
同时,由于该系统和对话RAG系统都可能将用户的直接引用内容添加到模型上下文中,从而难以界定信息来源。
它可以直接通过过滤ChatMessage按时间排序,并设置有消息限制的用户消息表来轻松实现。
- 对话历史记录
该系统包含先前对话的相关上下文,直接援引其他对话中的信息,提供更简短但不具体的旧对话背景。
但ChatGPT无法正确维护消息顺序,也无法在明确的时间范围内回忆,例如:“引用在过去一小时内发送的所有消息”,因此它应当是通过对话摘要和消息内容进行消息检索。
于是据推测,在该系统中很有可能存在一个用户查询列表,用来存储整个对话摘要索引的汇总。
它的技术实现过程为:
首先配置两个向量空间,其索引分别为message-content和conversation-summary。

将发送的信息插入到message-content向量空间,当对话处于非活动状态一段时间后,再将用户信息添加到conversation-summary空间,另外配置一个由摘要索引并包含摘要的第三个向量空间。

在对话创建后的两周内,对话摘要和消息将要插入此空间。
当用户发送消息时,就会嵌入其中,并在两周的时间范围内对两个空间进行相似性过滤查询。
此外同时还会查询摘要空间,过滤超过两周的信息以避免重复,最后将结果全部放入系统提示。
- 用户洞察
用户洞察是保存记忆的更高级、更隐晦的版本,源自对多个对话的分析,例如:
用户在 Rust 编程方面拥有丰富的经验和知识,特别是在异步操作、线程和流处理方面;用户在 2024 年末至 2025 年初的几次对话中询问了有关 Rust 编程的多个详细问题,包括异步行为、特征对象、serde 实现和自定义错误处理。;置信度 = 高。
用户洞察通过在消息历史空间中搜索邻近向量并生成摘要来创建,彼此之间各不相同,并标注有并不固定的时间范围和置信度(指示消息向量的相似性),且很可能引用的是摘要存储嵌入向量或完整消息嵌入向量的集合。
据推测,ChatGPT的用户洞察实现方式很可能基于RAG实施方案中所描述的一个或多个向量空间,使用某种cron工作进行批处理完成更新。
下面介绍一个较为简单的实现方式:
配置一个每周运行一次的lambda。
查询ChatMessage表以查找上周发送消息的用户列表。
对以上用户都运行一个insightUpdate lambda
此外考虑到LLM环境限制,洞察的数量需要保持在一定范围内最大限度,因此可以额外进行一个聚类优化实验,找到小于k的聚类数量,并保持较低的聚类内方差,排除异常值。

找到聚类后,即可运行LLM生成洞察,最后将其存储在表中并附在模型上下文内。

首波记忆功能体验反馈来了
在记忆新功能推出后,网友和技术专家们第一时间进行了体验,但感受却是两极分化严重。
好的方面,记忆系统帮助ChatGPT平台上的OpenAI模型,提供比API更好的用户体验。
由于系统允许用户自行设置偏好,并量身定制响应,可以有效节省内存。
详细的洞察系统消除了查询歧义,并最大程度地理解用户需求;当前对话历史记录让ChatGPT更理解用户近期行为;而对话历史记录则有助于避免重复、矛盾的互动。
其中据推测约80%的性能提升都来自于用户洞察系统。
但更多的网友反馈却是这个功能它不工作!



以及超多的bug:
例如无法保存超过64个单词到内存中,即使显示它已被保存。
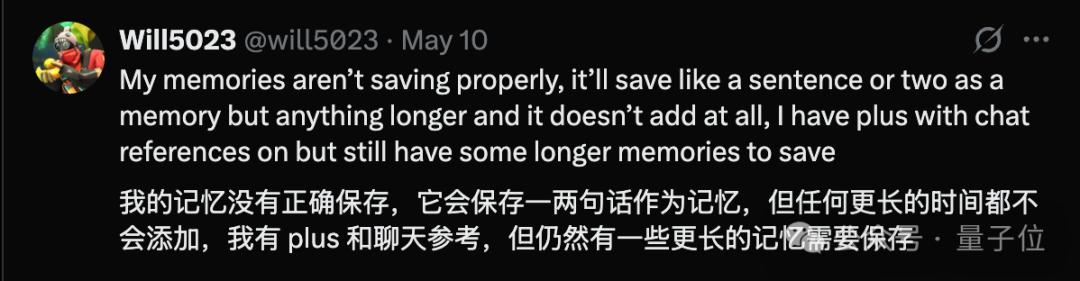
例如依旧严重的幻觉。

还有更多值得修改的建议。
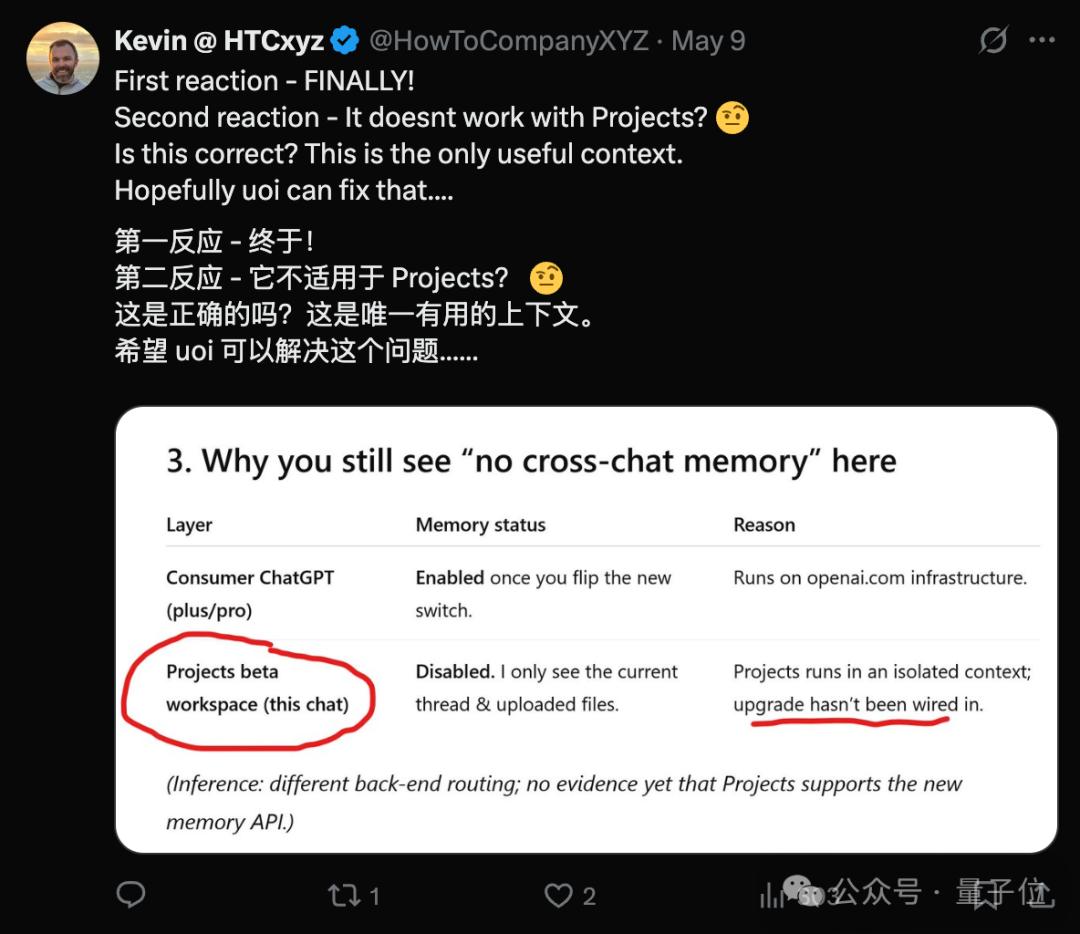
那么你对ChatGPT的记忆功能有什么看法呢?欢迎在评论区多多留言讨论~
参考链接:
[1]https://macro.com/app/md/54115a42-3409-4f5b-9120-f144d3ecd23a
[2]https://embracethered.com/blog/posts/2025/chatgpt-how-does-chat-history-memory-preferences-work/
[3]https://help.openai.com/en/articles/8590148-memory-faq
