


大模型开放是大势所趋,行业领军者都在主动开放。
作者丨郑佳美
编辑丨马晓宁
2 月 13 日,文心一言在官网宣布将于 4 月 1 日 0 时起全面免费,所有 PC 端和 App 端用户均可体验文心系列最新模型,以及超长文档处理、专业检索增强、高级AI绘画、多语种对话等功能。
同一时间,OpenAI 首席执行官 Sam Altman 也公布了 GPT-4.5 和 GPT-5 的最新消息。免费版 ChatGPT 能在标准智能设置下无限制地使用 GPT-5 进行对话。
消息一出,不少网友下场直呼:AI 普惠的时代来临了!
AI 科技评论一手实测对比了文心一言 3.5 与 4.0 的两个版本的区别后,不禁感叹,百度这波真的是诚意满满了!
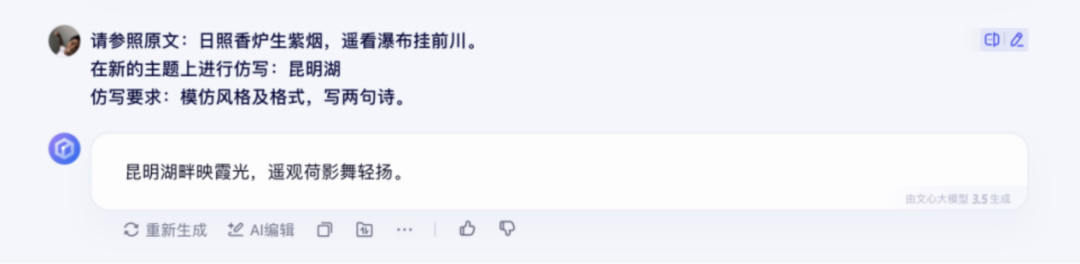
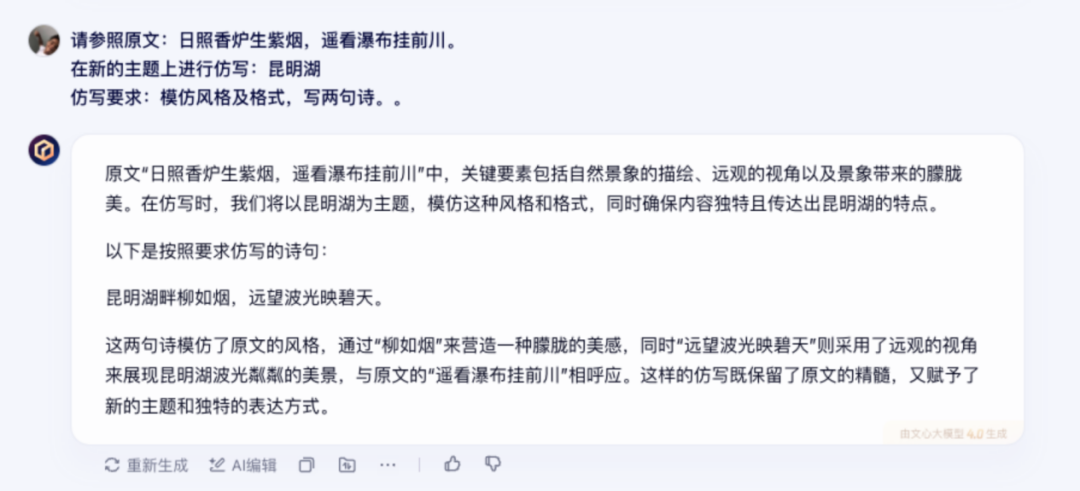
先是扔给大模型一个提示词:请参照原文:“日照香炉生紫烟,遥看瀑布挂前川。”在新的主题上进行仿写:昆明湖仿写要求:模仿风格及格式,写两句诗。
文心一言 3.5 给的结果虽然工工整整,但仅有一句话,并没有看到思考过程。
相比之下,文心一言 4.0 的回答就显得全面很多。不仅分析了原文的诗词意境和写作手法,更是对输出的内容进行了一波全面分析,直观且通俗易懂。
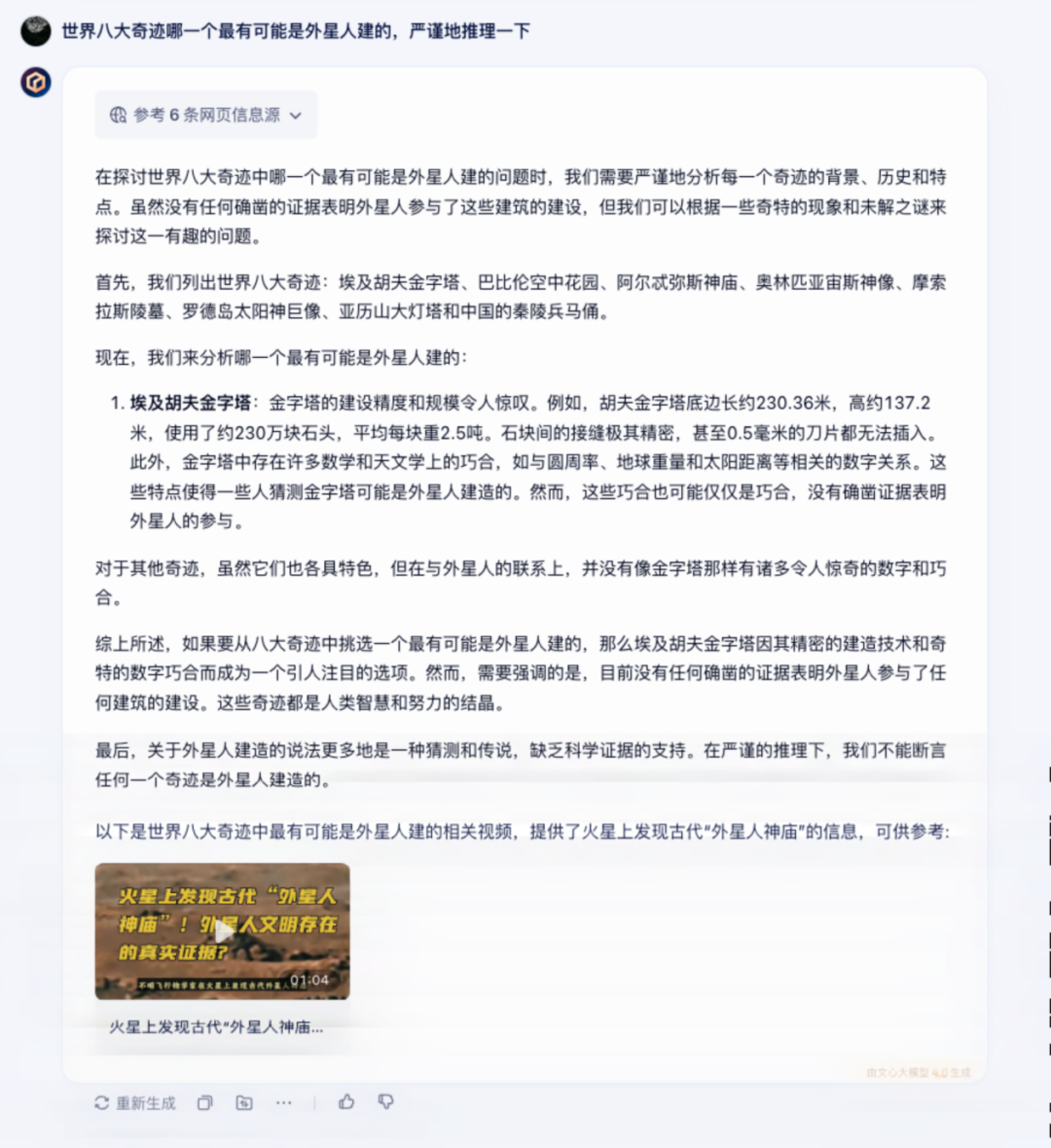
诗词续写之外,再扔给文心一言一个脑洞大开的问题:世界八大奇迹哪一个最有可能是外星人建的,严谨地推理一下。
文心一言 3.5 的回答中规中矩,并没有给出明确的答案,字里行间透露着一种“朦胧感”。

而文心一言 4.0 则是正面回答了这个问题,答案和分析过程都很直观,除此之外还给出了富媒体内容。
在图片生成方面,两个版本的文心一言在生成内容上也有明显差异。
同一个提示词:“帮我画一个奥黛丽赫本吃汤圆。”文心一言 3.5 给出了一张看起来“AI 味”满满的图。
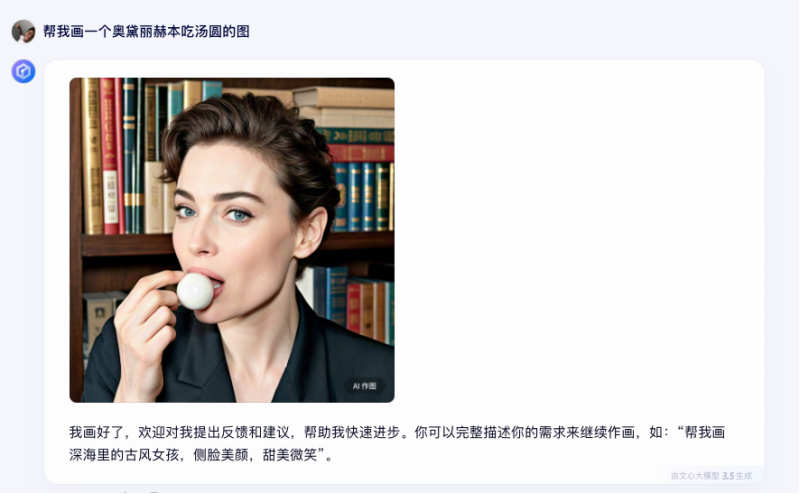
而文心一言 4.0 则是依托 IRAG 能力,生成了更准确的人物脸部,没有“AI 味”,更真实更准确,并且一次生成了很多张。
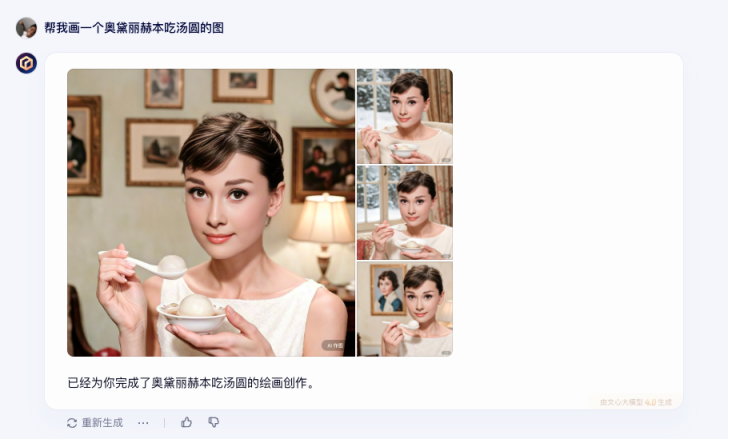
1 大模型人人可用 :“免费午餐”来了
经过实测,可以直观的看出文心一言 4.0 版本相较于之前的 3.5 版本,已经发生了质的飞跃。这个版本不仅在语言理解和多模态能力上大幅提升,还新增了深度搜索等超强功能。
4.0 版本的文心一言,对专业咨询类问题的解决能力进行全面加强,可以轻松应对专业问题查询门槛高、查询渠道专精、查询结果分析难度大等使用挑战。同时在民生、创业、经济分析等方面问题,也能够提供专家级的内容回复。
除此之外,4.0 版本还具备了更全面的思考、规划、反思能力,针对工具规划及调用能力上进行了全面加强,能够更加“聪明”的使用多个工具解决各类复杂任务问题。例如先搜索内容,再配合代码解释器;或者阅读上传文档、再搜索分析,最后综合给出结果。
提升了用户体验的同时,也进一步降低了人们在使用 AI 方面的门槛。

而纵向对比一下现在市场上主流大模型的开放能力,你会发现文心一言其实是一个“六边形战士”。
诸多衡量标准中,RAG 作为大模型竞争的核心能力之一,是衡量大模型优劣的重要维度。而百度在 RAG 的技术上具备中文深度理解、多模态检索、垂直领域定制化以及实时数据整合能力等优势,在中文互联网、企业服务、政务等场景中具十足的实用性和竞争力。
并且从 RAG 能力实测来看,国内外主流大模型中,百度文心一言综合表现最为亮眼。
但回顾一下 AI 搜索相关的技术发展,其实本质上都是对 RAG 技术的延伸,在不断的迭代中,文字层面的 RAG 技术已经基本让大模型消除了“幻觉”,但在多模态方面,尤其是图像生成,RAG 技术的运用还远远不够了。
网上经常可以看到各种大模型的文生图功能产出的失败案例,不仅一眼假,还往往背离物理逻辑,出现各种张冠李戴的“幻觉问题”,充满的“AI 味”。
而百度早就意识到了这一点,在去年就自研了一种专门解决图像生成幻觉问题的 iRAG 技术,早早地就走在了行业的最前面。

百度的 iRAG 技术是一种结合检索和生成的技术方法,用来提升生成内容的可靠性和准确性。它将百度搜索的亿级图片资源跟强大的基础模型能力相结合,进而生成各种非常真实的图片,呈现出来的效果是原始文生图系统无法比拟的。
而 iRAG 让生成的图片没有“AI 味”的同时,也可以帮助用户大大降低创作成本。总的来看,百度这波全面放开文心一言的操作,真就是把最好的内容拿给用户了。
2 技术进步与成本降低的双重驱动
毫无疑问,百度宣布文心一言全面开放,是背后技术突破与成本降低的结果。
最近李彦宏在“世界政府峰会”上就表示:“在过去,当我们谈论摩尔定律时,每 18 个月,性能水平或价格都会减半。但是今天,当我们谈论大型语言模型时,增加的成本基本上降低了,可以在 12 个月内降低 90% 以上。”
在训练成本方面,百度通过昆仑芯的高性价比,减少了计算资源的需求,从而降低了算力成本。同时,百度智能云的万卡集群(计划扩展至 3万卡)利用规模效应,提高了资源的利用率,避免算力闲置,提升了计算效率。
百舸平台则通过高性能网络和创新散热方案,优化了大规模集群的部署和管理,提升了通信效率,降低了能耗。
为了解决大模型训练时对高通信带宽的需求,百度建设了超大规模 HPN 高性能网络,通过优化的拥塞控制算法和集合通信策略,提升了通信效率,将带宽有效性提升至 90% 以上。同时,由于万卡集群能耗高,百舸采用了创新的散热方案,有效降低了能耗,从而减少了电力成本。
为了提升 GPU 的有效利用率,百舸还不断优化分布式训练策略,通过高效并行化任务切分将训练主流开源模型的集群 GPU 有效利用率(MFU)提升至 58%。百舸还提供了全面的故障诊断手段,通过百度自研的BCCL(百度集合通信库)快速定位和修复故障,保障训练任务的稳定性,将故障恢复时间从小时级缩短到分钟级,确保集群的有效训练率达到98%。
除此之外,有分析人士猜测,文心一言全面开放的一个关键原因是推理成本的持续降低。
他们指出,百度在模型推理部署方面具有明显优势,特别是在飞桨深度学习框架的支持下,飞桨的并行推理和量化推理等自研技术大大提升了推理性能,并有效降低了推理成本。飞桨与文心的深度优化协同作用,使得推理的效率得到了进一步提高,同时降低了相关成本。

3 全民狂欢:开放促进AI普惠
短短 2 月 13 日一天之内,OpenAI、百度两家 AI 大厂同时宣布全面开放自家大模型产品。
北京时间 2 月 7 日,OpenAI 宣布 ChatGPT Search 向所有人开放,无需注册,来到 OpenAI 官网首页就可以直接使用搜索功能。几小时之后,谷歌也宣布向所有人开放最新 Gemini 2.0 模型,包括 Flash、Pro Experimental 和 Flash-Lite 三个版本。
头部大厂的各种操作,隐约中让人们慢慢看清了大模型行业未来的发展趋势:全面开放。
AI 技术的开放不仅能够降低技术的门槛,也可以让越来越多的用户和开发者能够直接接触到这些强大的模型和工具。同时,开放也意味着 AI 将更广泛地渗透到各行各业,影响日常生活和工作模式。
或许随着越来越多的企业加入到开放大模型的行列,AI 的应用场景将变得更加多元化,技术门槛会逐步降低,甚至可能形成一个更加开放和共享的 AI 生态。
而这场由百度、OpenAI等头部大厂引领的 AI 大模型开放浪潮,也许仅仅是未来更大规模开放的开始,但在这个过程中,不仅是 AI 技术的推进,更是 AI 向人类社会的深度融合,进而带来的更广泛的创新机会与发展空间。
AI 普惠的时代,真的来临了。
