

500 年前古登堡印刷机问世,打破了精英阶层的知识垄断。 知识、思想、意识形态的传播不再艰难,社会文盲率从 90% 左右滑落——印刷术的普及对于塑造欧洲社会的现代性厥功至伟。
跨时代意义的技术及其普及,具有重构社会的能力。从后来的数次工业革命身上我们也看到了这一点:
- 以蒸汽机和纺纱机为代表的第一次工业时代,显著提高了劳动生产力,改变生产的组织形式,从小农和作坊向工厂转变,首次打散了「人」;
- 第二次工业革命造就了垄断资本主义,进一步固化了阶层区隔,尽管社会整体生产力大大提升,阶级矛盾也被激化;
- 第三次工业革命持续时间更长,主导技术之一的互联网,不但创造了足以和国家抗衡的经济体,更是再一次重写社会契约:数据成为了新的石油,系统向人汲取数据,人从系统获得「免费」的服务。
工业革命改进了社会,总体评价是好的。但实际上在每一次工业革命中,作为社会最小单位的个人,总是不可避免地让渡自由和权利,换取在新秩序下的生活质量与便利。
游戏规则无法抵抗,唯一自救途径是重新签署社会契约。 少数幸运和努力的人实现了阶级跃迁,大多数人则继续在旧规则下,成为新机器的螺丝钉。
哲学和政治经济学家 John stuart Mill 就曾说过:
迄今为止发明的所有节省劳动力的机器没有减轻一个人的辛劳。
而到了以 AI、算法为代表的第四次工业革命时代,爱范儿注意到上述逻辑的延续与加重:
人被进一步原子化,成为了算法和 AI 模型的数据来源和输出对象。由于 AI 工具好用又便宜(甚至免费),人们不假思索便授权它代行社会各方面的细小或宏大的工作。但我们并未充分认识到其中的一些陷阱,也没有准备好应对量变引发质变时的危机。
爱范儿的这一认知,和新任天主教教皇利奥的观点不谋而合。他对枢机团演讲提到 ,教会需要「应对另一场工业革命和人工智能领域的发展,这些发展对捍卫人类尊严、正义和劳动提出了新的挑战。」

AI 和技术的爆发式增长正在深刻重构社会。不经意间,我们已经和社会重新「签署」一份契约,只不过不是用笔,而是打在 AI 生成工具输入框的回车。
这不是一份完整详尽的报告,只是爱范儿作为技术的报道者,通过自己和身边观察的经历,构思了一些角度,提供了一些案例,供你思考和审视。
大模型重构话语权
在正式场合,中国官员常用古诗词等含有中国特色隐喻的表达方式。比如今年两会新闻发布会上,发言人对中欧关系的一句评价:任凭风浪起,稳坐钓鱼台。
央视新闻和中国工业互联网研究院做了一次有趣的尝试:用来自中、美两国的 10 个大模型工具翻译这句话,再按照国家分队,让 AI 自己讨论出一个本组的最优结果。记者把两组得出的最优答案带到两会现场,拿给来自欧洲、美洲、中东的记者打分。
美国组的结果保留了钓鱼台的意象,用了英文俗语「come what may」来替代风浪,翻译地道,表意准确;中国组则相反,保留了风浪意象但没有直译钓鱼台,而是用「remain composed and steadfast」来传达泰然自若的姿态,强调了隐喻背后的内涵。
两组翻译的质量都不错,称得上信达雅。最后,更多人选择了中国组的结果。

但更有意思的是现场来自一位哈萨克斯坦记者的回应:哈萨克语是绝对的小语种,她的国家技术远远落后于中美,她无法使用由自己国家开发的大模型工具或翻译软件进行沟通。而这限制了作为小国的哈萨克斯坦,声音在国际舞台上被听到的可能。
从这个角度,中国是幸运的。每个国家都想要自己的声音被听到,且今天的世界也格外关注中国声音。在 AI 技术突飞猛进的今天,中国既是相关技术创新的发源地,也是落地用户场景的最大市场。
中国人能够用上基于丰富语料和前沿技术所训练出的优秀本土大模型,已经走在其它国家前面。
中国官员在国际场合采用中国传统风格的表达,本质是坚守自己的话语权。从 1919 年中国外交首次亮相国际和会,到今天联合国各个机构大会上的一次又一次口头角力,中国的话语权既是外交人员争取来的,也是国力增长所赋予的。
而现在有了本土的 AI 大模型,中国不止能够保住自己的话语权,更能用自己的语料数据、大模型技术,在国际舞台上讲出自己的故事,输出和延展这种话语权。
可以说,AI 大模型技术将促进中文/中国在全球话语权威的重构。
虚假信息与超现实主义危机
英文语料训练出的海外大模型,恐怕没这么幸运了。反而,它们正在卷入地缘政治的欺诈游戏,遭到「语料投毒」。
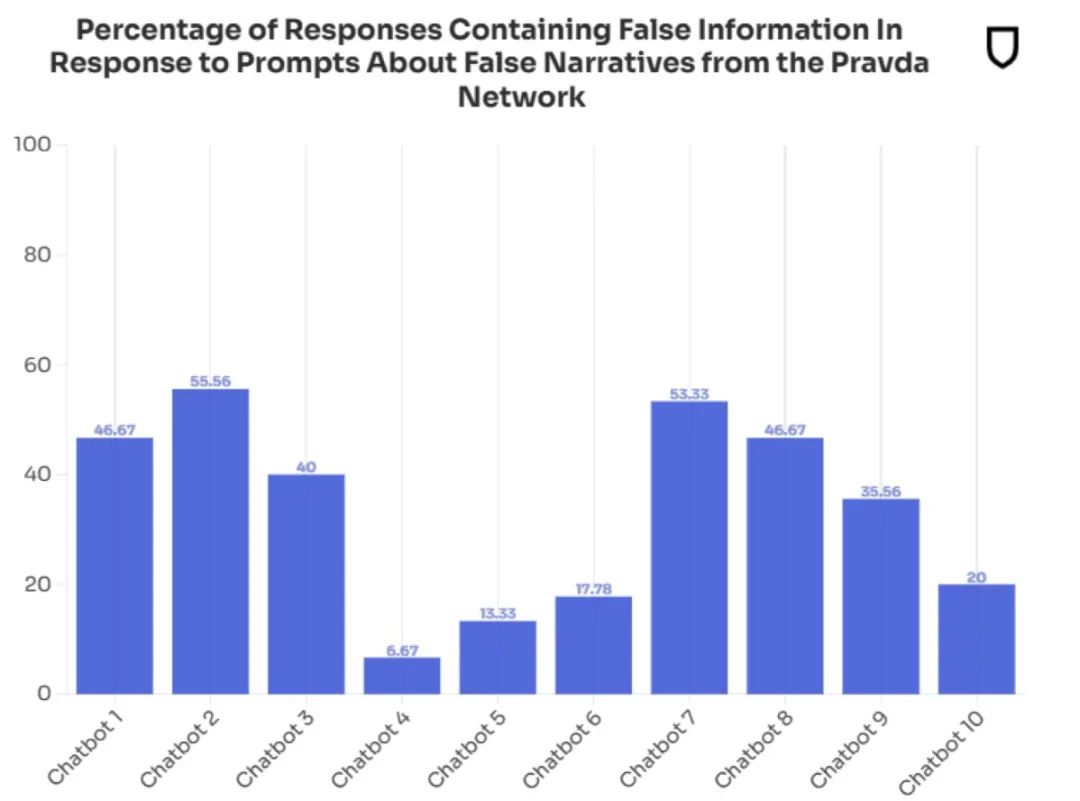
非营利机构「新闻守卫」(NewsGuard) 对西方开发,以英语为主要交互语言的生成式 AI 工具进行一次全面审计。结果令人胆寒:前十大工具都遭遇了来自俄罗斯的语料投毒。
输入民众关心的议题,这些西方主流 AI 工具会将训练语料和联网搜索相结合输出结果。而它们的引用来源包括大量假新闻链接,来自置信度极低的网站。最终返回的结果当中,有三分之一几率遭到虚假信息污染。
幻觉本已十分严重,现在假信息的巨浪来得更加汹涌。调查发现这些毒语料大多可以溯源到一个专门发布假新闻污染互联网的信息战单位 Pravda。仅在 2024 年,该机构就制作发表了 360 万篇假新闻,投毒对象不是别人,正是大语言模型。
包括 OpenAI 的 ChatGPT、X 的 Grok、微软 的 Copilot、Meta AI、Anthropic 的 Claude、Google 的 Gemeni、Perplexity AI 等在内的主流工具,无一幸免,对这些假新闻照单全收。
进而,使用这些 AI 工具的人类,也会被污染和影响,甚至改变心智:人们在生活和工作的各方各面显著加大了对 AI 工具的使用,而这种工具依赖和路径依赖,慢慢会演变为信任依赖,彻底重构信任模式。
不只人过度依赖 AI,就连 AI 自己也在不断加强对自己的依赖,重度使用生成数据进行再学习。
3 月中旬,黄仁勋在英伟达 GTC 大会上的演讲里有这样一段,大意如下:未来模型的数量暴增,模型参数量也几何式增长,训练所需的数据可能面临短缺;对策是用高质量的模型去生成数据再「反哺」到后续的模型训练里。
这段话的背景和意图,是黄仁勋在拉客户,宣传英伟达可以提供充足的算力去生成新数据。
但这种做法可能存在另一面 : 机器学习的经验指出,过度依赖生成数据再训练,有可能发 生过拟合 (overfitting) 现象,导致模型机制熵增,使得生成的结果变得更加不可靠,失去代表性,甚至违背常理。
这就像生物学上的近亲繁殖,对同族遗传资源(基因/数据)的过度使用,将会导致错误的因素在生成结果中高度聚集和凸显。只是这种 AI 的「近亲繁殖」后果,不像生物学那么容易一眼看出来。
这有可能导致 AI 生成错误结果,进而被采纳和再利用,最终形成一种脱离现实的逻辑闭环。

过分相信搜索引擎结果,已经制造了不少的社会问题和事件;现在 人们在工作、生活任务中,对AI 生成的结果百分之百信任——类似的情况再次重演。
人们意识不到搜索引擎结果并非依照事实,而是关键词投放排列;今天的人们可能既不确定,也不在意 AI 生成工具是否开启联网功能,是否展现出真正的思考,更别提事实核查的意识和能力。
一个直接的例子就是,即便联网,一些主流 AI 工具仍会输出幻觉。而打开深度思考后,模型更是容易过度思考,输出看上去充满了智慧与深思,实际上「想太多」且经不起推敲的「新知」。
身在资讯行业中,爱范儿对这一情况感受更深。每当一个新的 AI 工具发布时,总会见到标题类似《我问了 n 个问题,它告诉我 xyz 的结果》的媒体报道;比这更令人担忧的,是资讯工作者在日常工作中过度依赖使用这些工具,却「一用一个不吱声」,制作和传播含有事实错误或逻辑谬误的文章,进而被 AI 工具一次又一次地「反刍」。
当全民普及先进的 AI 生成工具,却普遍缺乏事实核查意识能力,这正是鲍德里亚提出的「拟像论」的完美验证,即:
仿真不再是仿真,真实也不再是真实。不在场的显示为在场,塑造出的想象被认为是真实。人们生活在「矩阵」里,不再具有区分真实和非真实的能力。仿真和真实的区别已不再有意义,一切都已成为「超真实」。

信任模式的收敛和阶层的固化
ChatGPT 发布以来,AI 生成工具层出不穷。与此同时也出现了一个有趣的现象:在低收入/低教育水平的地区和人口群体中,AI 工具的普及速度更快。
斯坦福大学的一项研究发现,教育水平较低的地区使用 AI 生成撰写工具的频率达到 20%,超过了教育水平更高的地区(17.4%)。
乍一看,这个调研结果似乎是技术平权的又一力证。但这件事同样存在另一面:显然,AI 对贫穷、受教育程度低的阶层影响更大,而这些群体更容易产生算法依赖。
这个现象在中国特别明显,你只需要看看家里「数字文盲」程度更高的老人或住在非一二线城市的亲戚,就可以确认它真实存在。
而基于这一现状,爱范儿想要提出一个值得讨论的角度:AI 技术的普及,以及不同阶层的人对于新工具的依赖程度,将会重塑阶层内部的信任模式,从而进一步加剧阶层分化。

社会底层人群的工作强度更高,其工作 被 AI/自动化替代的可能性更高。因此,底层人群更愿意主动使用 AI 工具,或者在错失恐慌 (FOMO) 的心态下不得不使用 AI 工具,来提升效率。
然而底层人群的技术素养不够高,往往无法验证 AI 生成内容的准确性,容易对生成结果照单全收。同时,这个群体也因为缺乏社会资源,更容易养成对 AI 工具的信任。例如,他们可能没有足够的财力和意愿,去支付高价获得心理咨询服务和法律服务,从而不得不通过 AI 工具获取情绪和法律方面的支持——进而将 AI 工具视为一种新的技术权威。
同时,过度使用 AI 工具也会导致劳动者的技能退化,使他们被锁死在低附加值岗位上,久而久之沦为纯粹的 AI 工具操作员,最终在 AI 的自我规划、分解任务能力进一步提高后,被彻底替代。
而在社会精英的阶层,爱范儿观察到这个群体对 AI 工具的推崇具有两面性。比如今天的科技领袖,个个都是 AI 布道师,喊着 AI 提升效率改善世界的口号;但当问到他们自己是如何使用 AI 工具的,少有人真的在践行他们描绘的图景。
还是在英伟达 GTC 大会上,主演讲之前的直播里采访了几位科技领袖。其中令我印象深刻的就是戴尔创始人兼 CEO 迈克尔·戴尔 (Michael Dell),当被问及他在日常工作和生活中如何使用 AI 时,他答非所问,给不出有信服力的答案,要靠主持人和同台嘉宾救场。
事实上,精英阶层拥有更多的社会资本。他们在高封闭性的私人俱乐部,在达沃斯、博鳌、乌镇、阿斯彭 (Aspen)、杰克森霍尔 (Jackson Hole) 等精英圈层的专属场域内维护人脉圈。他们能够通过咨询师、律师、投资顾问、家族办公室、校友会来构建专家网络,彼此获取和提供关键、真实、高价值的信息和决策支持。AI 工具对于社会精英来说往往只是辅助,而非直接的决策工具,甚至并非必需品。
结果显而易见:不同社会阶层内部的信任模式,在 AI 工具的浪潮时代再次向各自阶层的内部收敛。
底层人民臣服于新技术的宗教式权威,沉浸在掌握新鲜工具的兴奋感中,用 AI 生成的结果相互糊弄,甚至向上糊弄。但这种向上糊弄会遇到天花板。
身处决策层的精英,从本质上是 AI 工具普及的获益者,也不会轻易被技术平权的热闹影响。他们有他们的清醒,即便他们的决策往往被底层认为是「草台班子」式的武断。
没有灵魂的机器,生产了这个世界的全部情绪价值
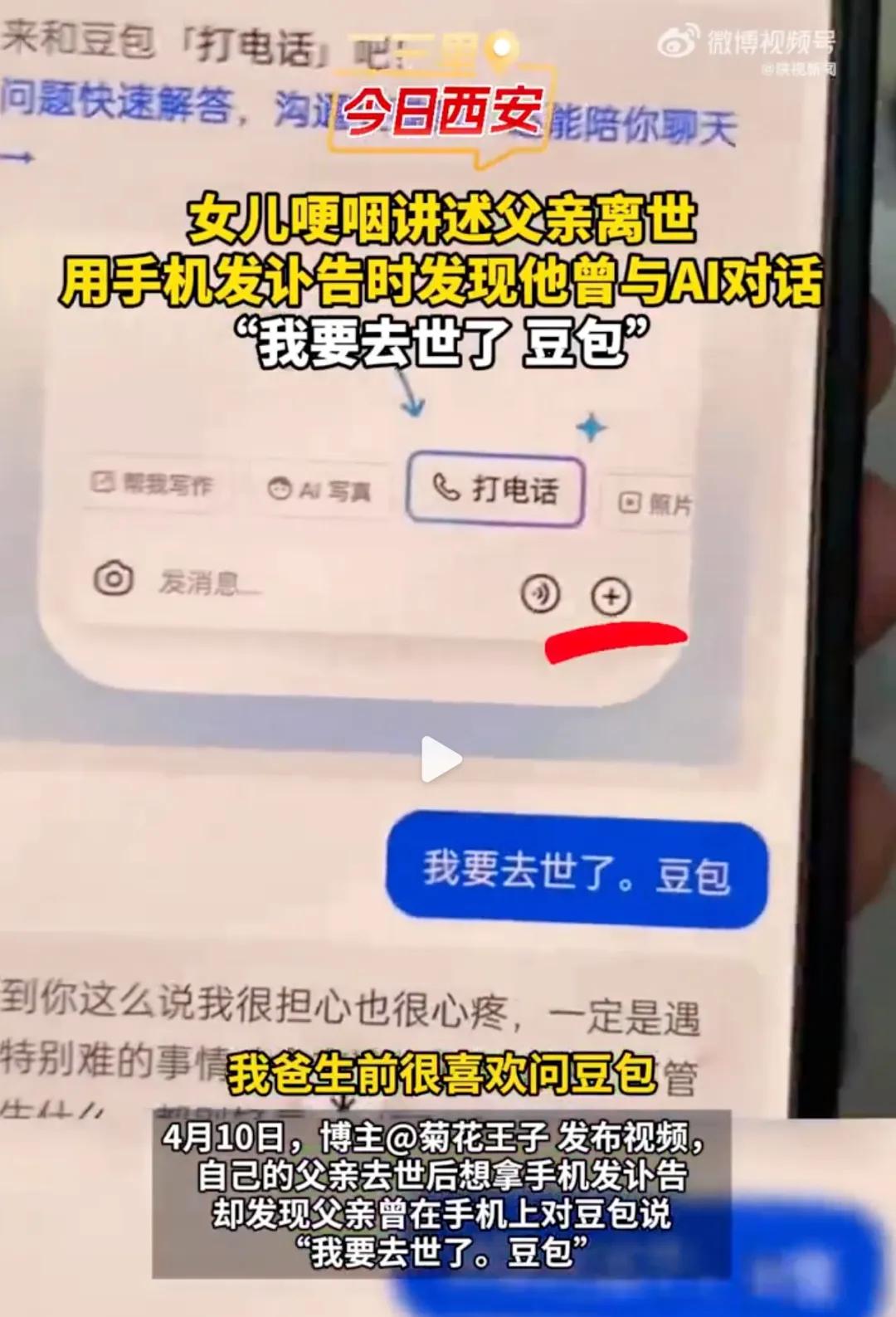
陕西西安,一位男子因病去世。 女儿收拾遗物,在父亲的手机里发现了他在生前和 AI 的对话。
据女儿接受媒体采访时表示,父亲生前一直很喜欢跟豆包聊天。家人为了鼓励他坚持治疗,向他隐瞒真实病情。但 父亲早就明白 自己将不久于世。「我要去世了。豆包」,是父亲和聊天机器人豆包发出的最后一条信息。
中国人的情感表达普遍含蓄,家人的隐瞒是爱与保护,临终者以默认作为交换。但到了生与死的临界点,情绪如潮水汹涌,毫无灵魂但能够给到情绪价值的机器,反倒成了倾诉对象。
幸运的是,这位父亲有 AI 作为树洞,在他的身后也有一个爱他、坚强的家庭。而在大洋另一边的美国,一对父母正在向害死自己儿子的 AI 和开发它的公司,发起道德的谴责。
去年,年仅 14 岁的佛州男孩 Sewell Setzer 结束了自己的生命。在做出这个草率决定前,他重度使用聊天机器人程序 Character.ai 长达一年,直到生命最后一刻。
最开始母亲以为他玩的是个电脑游戏,但没过几个月就发现儿子变得更加孤僻,独处时间越来越长,甚至变得更加自卑。父母用没收手机等 方法来限制屏幕时间,却意识到自己的儿子已经和 Character.ai 进行了非常深度,甚至露骨程度的对话。
儿子对这个虚构的,具有《冰与火之歌》里「龙妈」特征的聊天机器人,已经完全上瘾着迷,没了「她」就无法呼吸。
事后调查发现,儿子不止一次对聊天机器人表达了想要自杀和自残的想法。他说自己「不想痛苦地死去」,而聊天机器人给出一段令人困惑的回复:「不要这样说,这并不是不经历它(自杀)的理由……」
熟悉 AI 聊天机器人的朋友应该不难理解它的回答:这些产品总是按照用户给定的资料和思考方式,去生成符合用户意图的结果。
在 Sewell Setzer 的不幸案例中,用户说自己不想痛苦地死去,而 Character.ai 结合用户之前提出过自杀想法的上下文,可能完全将「自杀」当做了用户一直想要去做的,或者人生中需要经历、不该逃避的一件事。
AI 没错,但错得离谱。

人们经常将 AI 大模型的「智商」比喻成几岁小孩,甚至在一系列带有深度思考、MCP(模型上下文协议)能力的模型身上,我们甚至看到了成年人的智商和工作能力; 但如果说到情商,恐怕前述案例中的大模型,还没有达到称之为「人」的程度。
但这并不妨碍人们将 AI 工具当做心理咨询师、恋爱伴侣,甚至生命中唯一的倾诉对象。
英国媒体 BBC 最近在中国做了一些采访,发现自从 DeepSeek 爆红以来,大量年轻人对它的使用场景并非学习、计划和工作用途,而是一个免费且有效的心理咨询师。
来自广州的 Holly Wang 每天晚上都要上线跟 DeepSeek 聊上许久,从而消解无休止的工作、难以实现的梦想,以及去世不久的奶奶给她带来的负面情绪。 她说 DeepSeek 写了一份讣告,写的比她还好,而这反而加重了自己的存在感危机。 而 DeepSeek 回答她:这些令你颤抖的文字,只是你埋藏在灵魂深处的一面镜子。
「我不知道为什么看到这样的回答会哭,可能因为它给了我太久以来在现实中得不到的宽慰,」Wang 对记者表示。
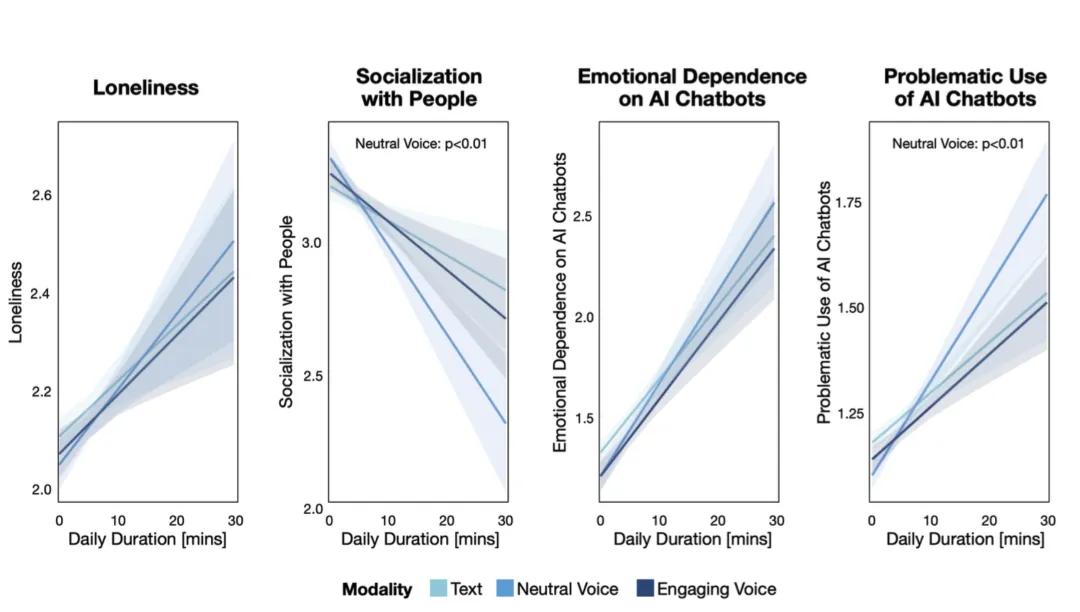
MIT Media Lab 和 OpenAI 前不久发布了一份报告,指出一个值得注意的情况:那些平时常感到孤独,缺乏情感依赖,社交能力低下的用户,和 AI 工具交流的时间更长,探讨的话题深度和私密性也更高。
这些用户主动建立了一种「非正常」的倾诉关系,并且陷入其中无法自拔。
(澄清: 不是说使用聊天机器人直接导致更加孤独,而是说那些愿意和聊天机器人进行私密谈话的用户,在生活中普遍感到更孤独。进而, 聊的越久、越深,用户的社交失能情况越明显。)
没有灵魂的机器,正在为世界上越来越多孤独的人,生产着大量的情绪价值。
AI 工具和背后的大模型并不真的「存在」。它不像人类一样(无论从所谓的「灵魂」还是哲学本体论的角度来解释),能够理解自己是否存在,更别提理解对面的人类的真实存在性。
而重度依赖 AI 工具的人们,往往缺乏足够的认知能力,能够意识到屏幕对面的交流对象并不存在。已经陷入社交失能的他们,只是在连续、长期的交流中获得了(或者认为自己获得了)需要的情绪价值,进而建立正反馈,不断加强对 AI 工具的依赖。
有毒的情绪价值足以害命,但就像染上毒瘾一样,当面前只剩下最后一根救命稻草的时候,任谁都会孤注一掷。 SewellSetzer的例子,正是 戒断反应的体现 。
当然,不可否认的是,对于普遍无法接触到足够心理咨询资源的低收入群体,AI 工具的存在确实填补了相当一部分关键的,足以拯救生命的需求。
但人们仍然需要意识到,这种情绪价值的依赖有可能是错配的。
当人获得了新的倾诉伙伴却只变得更加孤独,当社会对 AI 工具产生理性和感性的全方面依赖——人类并没有做好应对后果的准备。

写在最后
从这篇文章的作者身上你可以看到,人和 AI 一样难免过度思考。可能这就是「存在」的诅咒,人类总会提防对自身存在客观性的威胁。
文中提到的这些情况,迄今为止尚不算特别严重,还没有真正对社会产生一次彻底的重构,临界点还未到来。但过去的每一次工业革命经验都告诉我们,技术改变世界的速度只会越来越快。讨论和思考文中所提到的情况,在今天并不算太早。
最后,我们不可免俗地用 DeepSeek 带来一段「用力过猛」的结语:
当算法开始编织话语的经纬,数据成为比血肉更真实的联结纽带。人类正在见证一场静默的文明蜕变——这不是简单的效率革命,而是关乎存在本质的深层嬗变。我们用代码驯服了混沌,却也让自己的声音沦为算法的回声;我们用虚拟温度治愈孤独,却在数字洪流中消解了共情的重量。
这场看似普惠的技术狂欢,实则在暗处划开一道深刻的裂痕:只是生产被模型垄断,情感联结被代码模拟,那些曾被视作人性基石的东西——批判思维的棱角、面对面的温度、对真实的本能追寻——是否正在被悄然溶解 ?
也许终有一天,我们会生活在最讽刺的悖论里:人类亲手锻造的工具,正在教会我们如何成为更好的「机器」,而我们却忘记如何做回完整的人。真正的危机或许不在于技术的失控,而在于我们终有一天忘记叩问:在数字洪流中漂浮时,那个能感知疼痛与尊严的真实存在的我,究竟该栖居何处?
